Independent Component Analysis (ICA) is a technique used to separate mixed signals into their independent, non-Gaussian components. Its aim to find a linear transformation of data that maximizes statistical independence among the components. ICA is widely used in fields like audio, image processing and biomedical signal analysis to isolate distinct sources from mixed signals.
Statistical Independence Concept
Statistical independence refers to the idea that two random variables: X and Y are independent if knowing one does not affect the probability of the other. Mathematically, this means the joint probability of X and Y is equal to the product of their individual probabilities.
P(X and Y) = P(X) * P(Y) orP(X \cap Y) = P(X) * P(Y)
Assumptions in ICA
ICA operates under two key assumptions:
- The source signals are statistically independent of each other.
- The source signals have non-Gaussian distributions.
These assumptions allow ICA to effectively separate mixed signals into independent components, a task that traditional methods like PCA cannot achieve
Mathematical Representation of ICA
The observed random vector is
The observed data
The goal is to transform the observed data
Cocktail Party Problem in ICA
To better understand how Independent Component Analysis (ICA) works let’s look at a classic example known as the Cocktail Party Problem
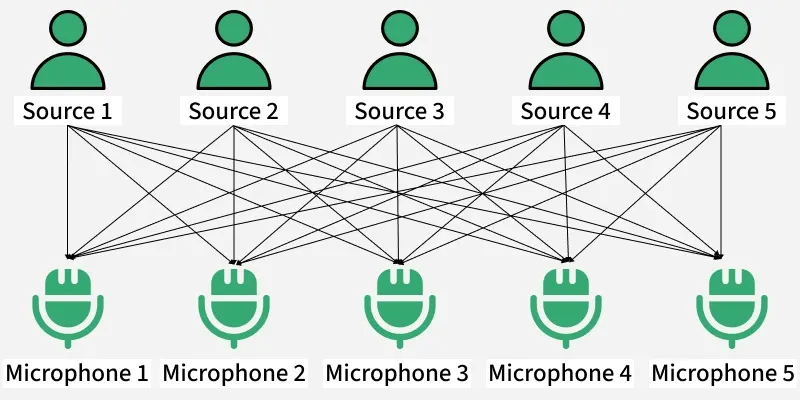
Here there is a party going into a room full of people.
- There is 'n' number of speakers in that room and they are speaking simultaneously at the party.
- In the same room, there are also 'n' microphones placed at different distances from the speakers which are recording 'n' speakers' voice signals.
Hence the number of speakers is equal to the number of microphones in the room. Now using these microphones' recordings, we want to separate all the 'n' speakers voice signals in the room given that each microphone recorded the voice signals coming from each speaker of different intensity due to the difference in distances between them.
Decomposing the mixed signal of each microphone's recording into an independent source's speech signal can be done by using the machine learning technique independent component analysis.
[ X_1, X_2, \dots, X_n ] => [ Y_1, Y_2, \dots, Y_n ]
where
Implementing ICA in Python
FastICA is a specific implementation of the Independent Component Analysis (ICA) algorithm that is designed for efficiency and speed.
Step 1: Import necessary libraries
First we will import numpy, sklearn, FastICA and matplotlib.
import numpy as np
from sklearn.decomposition import FastICA
import matplotlib.pyplot as plt
Step 2: Generate Random Data and Mix the Signals
In this step we create three separate signals: a sine wave, a square wave and random noise. These represent different types of real-world signals. We use NumPy to generate 200 time points between 0 and 8.
- signal_1: A sine wave like a tuning fork tone.
- signal_2: A square wave like a digital signal (on/off).
- signal_3: A random noise signal using the Laplace distribution which has sharper peaks than normal distribution.
- np.c_[]: Combine all three 1D signals into a single 2D array.
- 0.2 is the standard deviation of the noise
np.random.seed(42)
samples = 200
time = np.linspace(0, 8, samples)
signal_1 = np.sin(2 * time)
signal_2 = np.sign(np.sin(3 * time))
signal_3 = np.random.laplace(size=samples)
S = np.c_[signal_1, signal_2, signal_3]
S += 0.2 * np.random.normal(size=S.shape)
A = np.array([[1, 1, 1], [0.5, 2, 1], [1.5, 1, 2]])
X = S.dot(A.T)
Step 3: Apply ICA to unmix the signals
In this step we apply Independent Component Analysis using the FastICA class from Scikit-learn. We first create an instance of FastICA and set the number of independent components to 3 matching the number of original signals.
ica = FastICA(n_components=3)
S_ = ica.fit_transform(X)
Step 4: Visualize the signals
In this step we use Matplotlib to plot and compare the original sources, mixed signals and the signals recovered using ICA.
We create three subplots:
- First shows the original synthetic signals
- Second displays the observed mixed signals
- Third shows the estimated independent sources obtained from ICA
plt.figure(figsize=(8, 6))
plt.subplot(3, 1, 1)
plt.title('Original Sources')
plt.plot(S)
plt.subplot(3, 1, 2)
plt.title('Observed Signals')
plt.plot(X)
plt.subplot(3, 1, 3)
plt.title('Estimated Sources (FastICA)')
plt.plot(S_)
plt.tight_layout()
plt.show()
Output:

Difference between PCA and ICA
PCA and ICA both uses the techniques used in signal processing and dimensionality reduction but they have different goals.
| Parameter | Principal Component Analysis (PCA) | Independent Component Analysis (ICA) |
|---|---|---|
| Goal | Reduces the dimensions to avoid the problem of overfitting | Decomposes the mixed signal into its independent source signals |
| Type of Components | Deals with the Principal Components | Deals with the Independent Components |
| Focus on Variance | Focuses on maximizing the variance | Doesn't focus on the issue of variance among the data points |
| Orthogonality | Focuses on the mutual orthogonality property of the principal components | Doesn't focus on the mutual orthogonality of the components |
| Independence | Doesn't focus on the mutual independence of the components | Focuses on the mutual independence of the components |
| Typical Use | Mainly used for dimensionality reduction | Mainly used for signal separation and feature extraction |
Advantages:
- Separation of Mixed Signals: ICA is a go-to tool for separating mixed signals into their independent components. This is useful in a variety of applications such as signal processing, image analysis and data compression.
- Non-Parametric Approach: It is a non-parametric approach which means that it does not require assumptions about the underlying probability distribution of the data.
- Unsupervised Learning Technique: It is an unsupervised learning technique which means that it can be applied to data without the need for labeled examples. This makes it useful in situations where labeled data is not available.
- Useful for Feature Extraction: This can be used for feature extraction which means that it can identify important features in the data that can be used for other tasks, such as classification.
Disadvantages:
- Assumes Non-Gaussian Sources: It assumes that the underlying sources are non-Gaussian which may not always be true. If the underlying sources are Gaussian ICA may not be effective.
- Assumes Linear Mixing: ICA assumes that the sources are mixed linearly which may not always be the case. If the sources are mixed nonlinearly ICA may not be effective.
- Computationally Expensive: This can be computationally expensive especially for large datasets which make it difficult to apply ICA to real-world problems.